Point Cloud information is very common in robotics , as it is often part of how robots see the world. In this project, a PyTorch model was trained to identify classes using Point Cloud data.
Introduction
RGB images are commonly used for object classification, but they have limited spatial context. In contrast, point clouds capture spatial geometry. Robots, equipped with sensors that capture point clouds, often see objects that are partially obscured. Classifying them helps the robot navigate and perform tasks.
Dataset
The dataset is composed of as follows : List of 3D points (size of 1024 each) and their RGB values corresponding to a label ((x,y,z,R,G,B) -> label).
An example of the format for one data point is as shown below:
1
| [(0.2,1.2,0.4,0,126,90),(0.1,2.2,1.4,12,10,120),(1.3,1.2,0.12,20,0,130),....] -> Banana
|
The dataset contains these classes (5 in total) : Apple , banana , bottle , bowl and cup.
The dataset was generated using Isaac Sim, a robotic simulator, to create more realistic and challenging data for real-world applications. Traditional point cloud datasets of object models often fail to replicate real-world scenarios, where RGB-D cameras or LiDAR sensors cannot capture the entire point cloud of an object. To address this, a dataset was generated using perception inputs from such sensors.
Object models scanned from the real world through the OmniObject3D dataset were sourced. These objects were randomly placed in Isaac Sim, where RGB-D images were continuously captured along a spherical trajectory.
The Isaac-Sim-generated data includes RGB and depth images (for converting into point clouds), segmentation masks for each object, and segmentation labels mapping RGBA values to object classes. It also provides camera intrinsics to convert depth images into accurate point clouds.

Top row: The image from IssacSim, Middle Row: Depth Information, Bottom Row: Segmentation data
Network Structure
The network was built on top of the PointNet network architecture (Qi, C.R. et al., 2016. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation), with added RGB data. The order of the points does not matter, as it the are pretty random, so some kind of a symmetric function is need (max pooling) and also the translation and rotation of an object should not matter so additional transformation layers were added (T-Net).
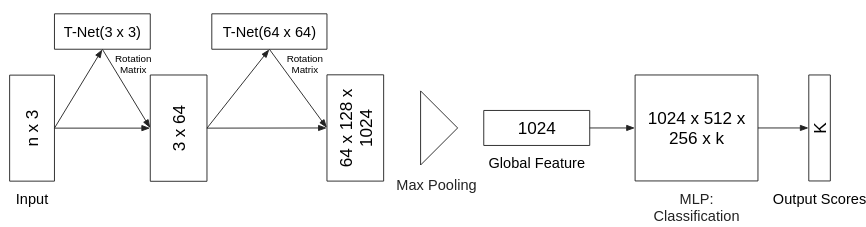
The original PointNet structure, as seen in Qi, C.R. et al., 2016
The canonical PointNet architecture is extended by incorporating RGB color channel information from the point cloud data. The additional 3 dimensions are processed through a 4-layer MLP, with max pooling applied to remove order bias. The resulting feature vector is then concatenated with the PointNet feature vector for classification.
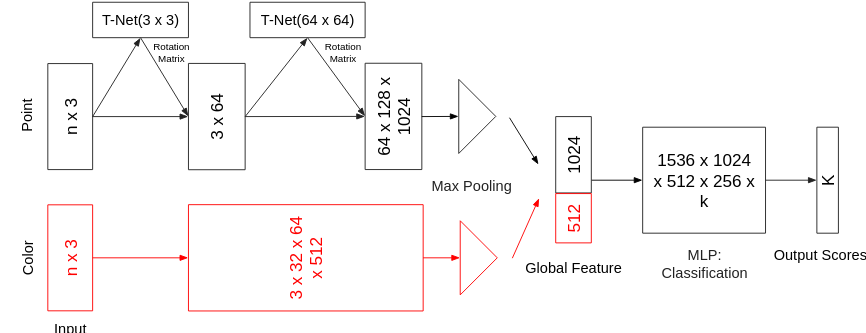
The modified PointNet structure, adding the RGB values.
(Drumroll…) The Results
The model achieved 80% accuracy on the training set and 70% on the test set. Here is the learning curve:
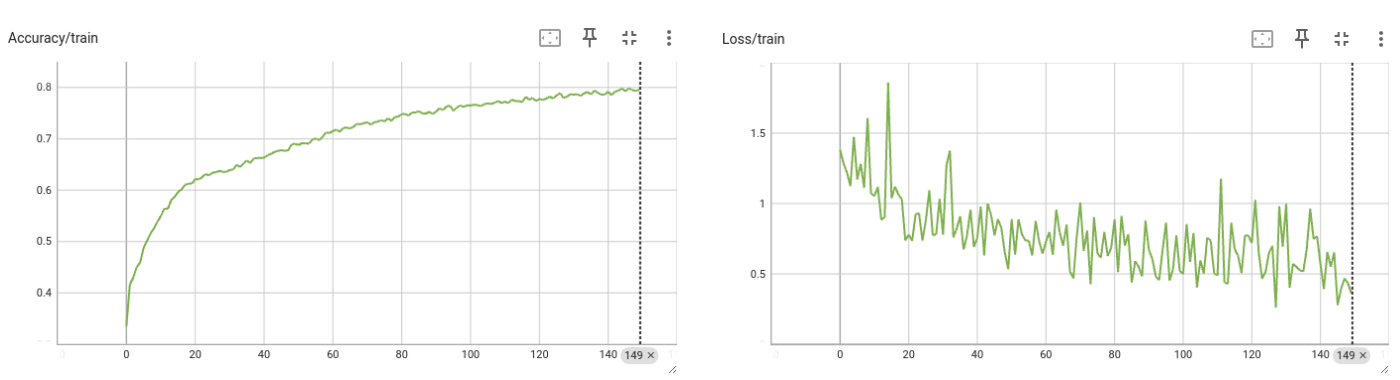
The Learning curves.
Comparison with other Methods (KNN)
Is this fancy neural network worth the hassle? Did we go way above our head? To test this, the network was put head to head against a more traditional method, which was chosen to be K nearest neighbors (KNN). KNN was practically useless , as it gave a accuracy of 27%, which is almost as good as just guessing (there are 5 classes).
Acknowledgments
This was a group project, and was done with these dashing individuals:
Zhengyang Kris Weng and Zhengxiao Han.