A reimplementation of ChatGPT 2 using pure PyTorch, using the GPT2 and GPT3 papers.

Introduction
Github Link
Large language models are everywhere now, but I didn’t want to treat them like a black box. I wanted to understand what’s actually happening under the hood instead of just calling it “AI,” so I set out to build GPT-2 from scratch—pure PyTorch and my own layers, end to end. The only exception was tokenization: I used Hugging Face’s Byte-Pair Encoding (BPE) to stay compatible with the GPT-2 vocabulary. In my view, building it from scratch—while a tough path—is the best way to develop a fundamental grasp of the model’s ins and outs.
Same Design, Different Scale
I implemented GPT-2 Small, which has about 124M parameters. Architecturally, it’s the same as larger models like GPT-2 Medium (345M), Large (762M), XL (1.5B), and even GPT-3 (175B)—the difference is simply scale (more layers, wider embeddings, and larger vocabularies). I chose to train the small model because I only had limited compute and time—training still took nearly 80 hours. That said, the code is modular and general enough that, in principle, it could scale up to handle much larger models too.
What’s different from Hugging Face’s implementation?
At a high level, my GPT-2 reimplementation still follows the standard decoder-only transformer stack (embeddings → transformer blocks → layer norm → LM head). But instead of leaning on Hugging Face’s monolithic GPT2Model, I split the architecture into smaller, modular sub-classes so I could see and control every moving piece. The trade-off was that I couldn’t just drop in Hugging Face’s pretrained weights—the structure didn’t match. I really wanted that capability, though, since being able to load official weights would let me verify that my implementation worked correctly before committing to long training runs. To solve this, I ended up writing a custom weight-loading script, which you can check out here.
flowchart TD
A["Tokens"] --> B["Token Embeddings"]
B --> C["Positional Embeddings"]
C --> D
subgraph D["Transformer Block x n"]
direction TB
LN1["LayerNorm"] --> MHA
subgraph MHA["Multi-Head Attention"]
direction LR
H1["Head 1 (Q,K,V)"] --> H2["Head 2 (Q,K,V)"]
H2 --> Hn["Head n (Q,K,V)"]
end
MHA --> PROJ["Concat + Projection"]
PROJ --> RES1["Residual Connection"]
RES1 --> LN2["LayerNorm"]
LN2 --> FFN["FeedForward (Linear - GELU - Linear)"]
FFN --> RES2["Residual Connection"]
end
D --> E["Final LayerNorm"]
E --> F["LM Head (weight-tied)"]
My GPT’s Structure Modulation
The Dataset
I trained on the FineWebEdu-10B Dataset, a high-quality filtered web corpus focused on educational and reliable content. The model was trained for 4 epochs, covering a total of 40B tokens.
Loss Function
I used binary cross-entropy (BCE) as the loss function.
Training Tricks and Optimizations
To make training faster, more efficient, and closer to the setup described in the GPT-3 paper, I introduced several training “tricks”:
- Gradient accumulation & scaling – My GPU memory wasn’t large enough to handle massive batch sizes directly, so I used gradient accumulation to simulate them while keeping training stable.
- Matrix Multiplication Precision – I trained using PyTorch’s “high” precision mode for float32 operations. This mode lets NVIDIA GPUs run matrix multiplications faster by slightly reducing precision (using formats like TensorFloat32 under the hood) while still being close to full FP32. In practice, it gave me better speed without any noticeable loss in model quality.
- Distributed Data Parallel (DDP) – I enabled multi-GPU training so I could fully utilize my hardware (2 × NVIDIA A6000), though the code itself is written to be hardware-agnostic.
- Large batch size (524,288 tokens) – Chosen as a power of two, both for efficiency on GPU hardware and to align with large-scale LM training setups.
- Custom weight initialization – Set the standard deviation to ( \text{std} = \frac{1}{\sqrt{n_{\text{embd}}}} ), which stabilizes training and ensures the initial loss starts around the expected value:
\[\mathcal{L}_0 = -\ln\left(\tfrac{1}{Vocab\space Size}\right) = \ln(Vocab\space Size) \approx \ln(50257) \approx 10.82\]
-
FlashAttention – Replaced the vanilla attention mechanism with FlashAttention, a more memory- and compute-efficient implementation that allowed longer sequences and faster training.
- Optimizer Tweaks – Tuned the AdamW hyperparameters to match those reported in the GPT-3 paper (learning rate, betas, weight decay, etc.) to keep training behavior consistent with large-scale implementations.
- Gradient clipping – Transformer training often involves very large gradients, especially early in training or when using long sequences, which can cause exploding gradients. Clipping enforces a maximum norm on the gradients, preventing any single update from destabilizing training and keeping the loss curve smooth.
- Learning Rate Schedule (Cosine Decay) – To match the GPT-3 paper, I implemented a custom scheduler that linearly warms up the learning rate for the first steps and then decays it using a cosine curve. This approach smooths training: warmup prevents unstable updates at the start, while cosine decay gradually lowers the learning rate toward a minimum value so the model can converge more stably.
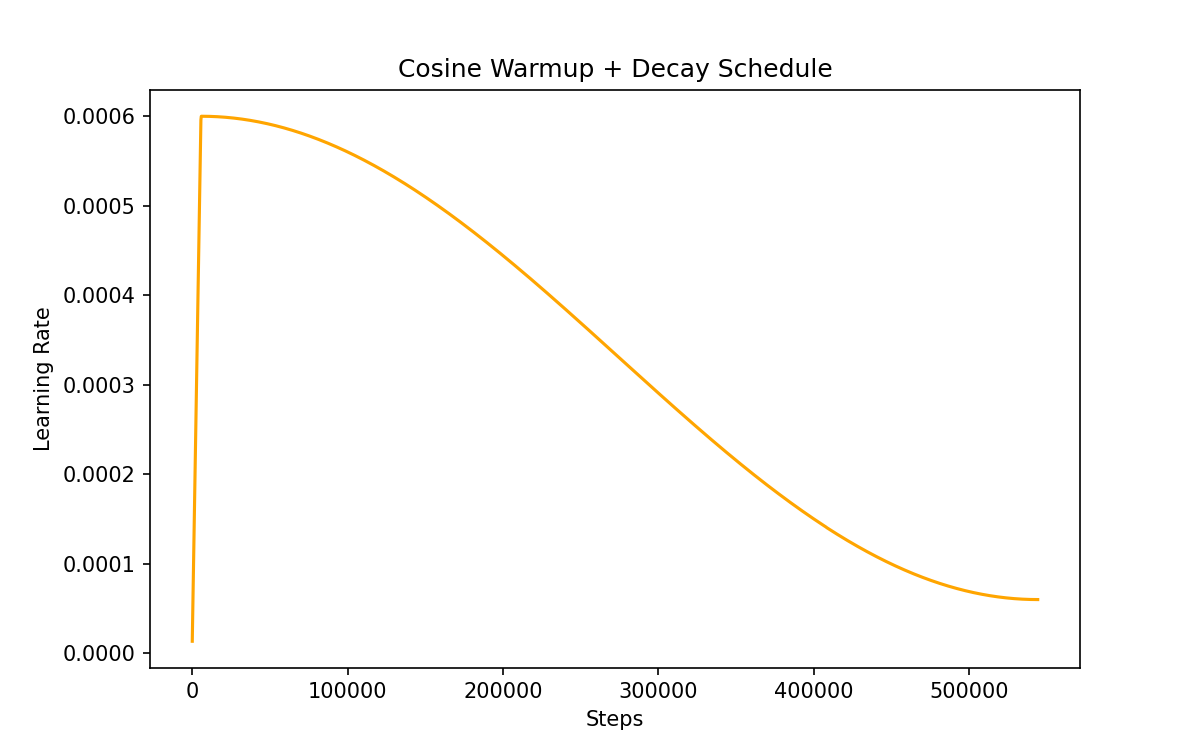
The Cosine Annealing with warmup for the learning rate
The Results
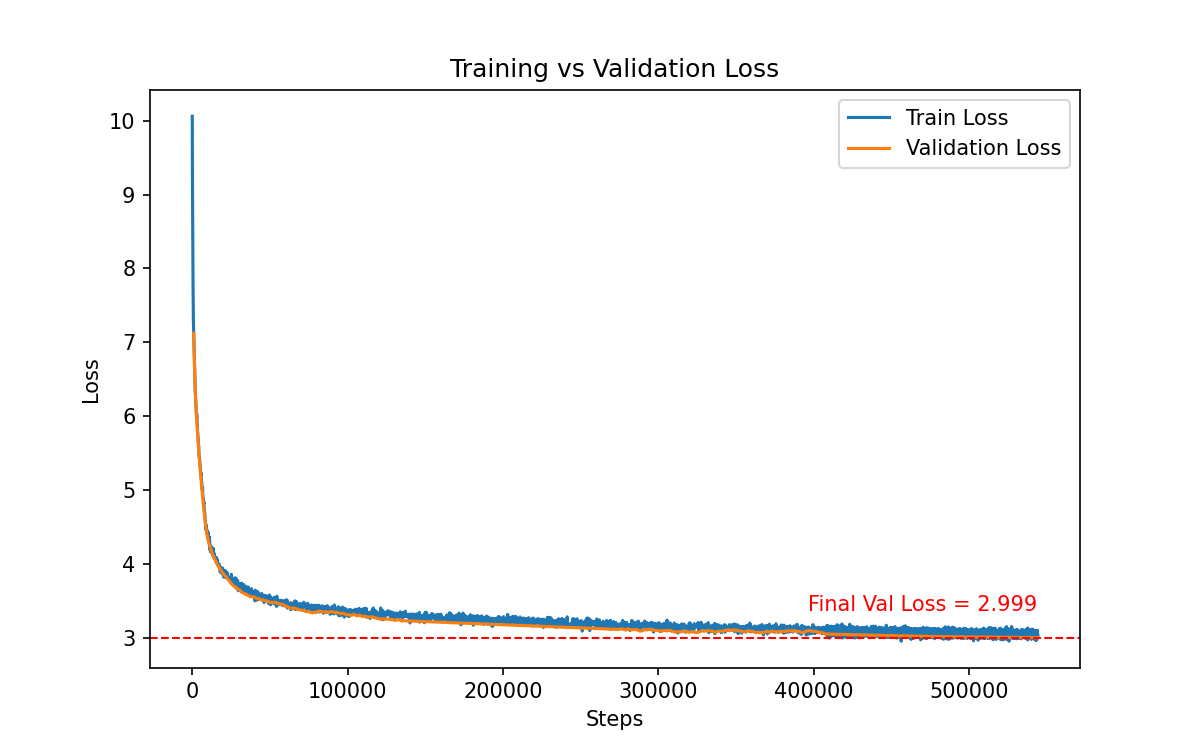
The training and validation loss across the training
The model reached a final validation loss of 2.99, which is right in line with expectations for GPT-2 Small–scale training. That was a satisfying checkpoint: it meant the architecture was working as intended, the training loop was stable, and all of my “under the hood” optimizations were actually paying off.
To give a feel for the outputs, here are two sample generations from the model when prompted with “Hello, I’m a language model”:
1
| Hello, I'm a language model, I'm really interested in the semantics of how computers work, and the most current model is a model of how humans process. How computers get the ability to understand language is a very simple question, however I know computer technology has evolved over the years, I still hope for the future. I guess if we were the ones who could imagine how things worked in a computer system, it would be cool. In order to understand how computers work, we need to know what it's not, in this model we get a lot of information from humans, you can hear different sounds when going over the airwaves of a particular building, how does it generate or what are the different "brain" features? As a computer system we can think about how computer systems work by collecting lots, each piece of information one by one, then converting it to a list of sounds. What is the machine that is doing this? What are some of the words humans use to describe speech
|
1
2
| Hello, I'm a language model, I'm an author, I'm just starting a new language, I'm a computer scientist, I've been doing things over the past few years, now I'm beginning a new area of research, I'm doing research, I'm taking a field trip. My goal is to discover the answer to the questions in the context of what happens when you write computers. So that I understand what the problem is has done. Now it's so different from doing the computer science. So the language, we use, is to think, think how?
A computer scientist is someone whose job is to design, model, and implement computer systems. They are also known for their creativity, creativity, critical thinking capabilities. They are excellent in creative problem solving, they are able to see things before they can be solved, their ability to think in a natural, natural way, and their ability to make changes to the world, and their ability to have a lot of imagination
|
The outputs aren’t perfect (some repetition, some meandering), but they’re coherent, on-topic, and demonstrate the model actually learned the structure of natural language.
Takeaways and Conclusions
- Rebuilding from scratch was worth it – Writing every sub-class myself forced me to really understand what’s happening inside a transformer, instead of just treating it like a black box.
- Training is expensive—even at small scale – GPT-2 Small (124M params) still took ~80 hours on my setup, and I only trained on 40B tokens. Scaling to bigger models makes it clear why huge compute clusters are required.
- Engineering tricks matter – Gradient accumulation, DDP, FlashAttention, and a cosine LR schedule realy sped up the training.
- Transformers scale incredibly well – The same building blocks power everything from GPT-2 Small (124M params) all the way up to GPT-3 (175B+). My code is modular enough that, in principle, it can grow with more layers, wider embeddings, and bigger datasets—the core design doesn’t change, only the scale.